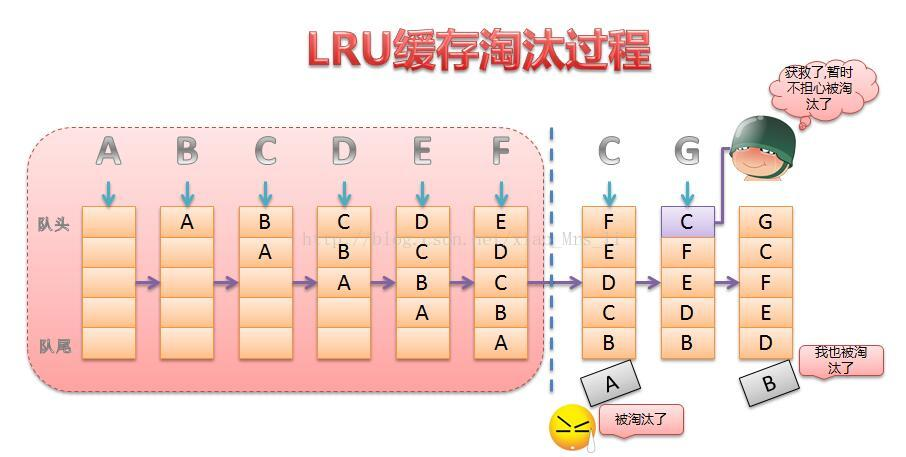
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
| type entry struct {
key string //对应key
value interface{} //key对应value
prev *entryU64 //前一个entry指针地址
next *entryU64 //下一个entry指针地址
}
type Cache struct {
entries map[string]*entry //记录所有key-value
size int //预设Cache最大可容纳key-value数量
onEvict func(key string, value interface{}) //超容量size时删除key-value的回调
head *entry //key-value链表的头指针
tail *entry //key-value链表的尾指针, 超容量size是删除的就是尾指针下对应entry
}
func New(size int, onEvict func(key string, value interface{})) *Cache {
if size <= 0 {
panic("invalid size")
}
return &Cache{
entries: make(map[string]*entry, int(float64(size)*1.5)), //map容量大约size的1.5倍
size: size,
onEvict: onEvict,
}
}
func (c *Cache) Set(key string, value interface{}) {
//尝试获取key下value, 可以看出Set方法是非线程安全的
e := c.entries[key]
if e == nil {
//key不存在,则直接添加打map, 并修改尾指针
e = &entry{key: key, value: value}
c.entries[key] = e
//每次添加的新key-value在链表都是头元素,同时调整原来的头指针和尾指针指向
if c.head == nil {
c.head = e
c.tail = e
} else {
c.head.prev = e
e.next = c.head
c.head = e
}
} else {
e.value = value
//数据存在,调整自己在链表的位置到头部
c.promote(e)
}
//超出预设size时,删除链表尾指针指向的entry并回调删除函数
if len(c.entries) > c.size {
evicted := c.tail
delete(c.entries, c.tail.key)
c.tail = c.tail.prev
c.tail.next = nil
if c.onEvict != nil {
c.onEvict(evicted.key, evicted.value)
}
}
}
func (c *Cache) promote(e *entry) {
//如果本来就是头指针则不调整
if c.head != e {
if c.tail == e {
//是尾指针情况下调整最新尾指针为当前的前一个元素地址
c.tail = c.tail.prev
c.tail.next = nil
} else {
//中间位置则当前元素的下一个地址为自己的下一个地址,上一个地址为自己的上一个地址
e.prev.next = e.next
e.next.prev = e.prev
}
e.prev = nil //调整自己为头元素后,自己的前一个地址为空
e.next = c.head //原头元素变成自己的下一个元素
c.head.prev = e //原头元素的上一个元素是自己
c.head = e //自己为头元素
}
}
func (c *Cache) Len() int {
return len(c.entries) //当前已记录数据长度
}
func (c *Cache) Get(key string) interface{} {
e := c.entries[key]
if e == nil {
return nil
}
//调整自己位置到链表头元素
c.promote(e)
return e.value
}
func (c *Cache) Delete(key string) {
e := c.entries[key]
if e == nil {
return
}
delete(c.entries, key)
//删除时修改自己的前后元素对应的上下地址指向
if len(c.entries) == 0 {
c.head = nil
c.tail = nil
} else if e == c.head {
c.head = c.head.next
c.head.prev = nil
} else if e == c.tail {
c.tail = c.tail.prev
c.tail.next = nil
} else {
e.prev.next = e.next
e.next.prev = e.prev
}
}
|